 OA系统
OA系统
 学院邮箱
学院邮箱
 教务管理
教务管理
 资源下载
资源下载
 English
English


91直播


91直播 /广东省存算一体芯片重点实验室杨玉超教授团队在国际上首次攻克大数据排序存算一体硬件系统
 发布时间:2025-07-07
发布时间:2025-07-07
 浏览次数:
浏览次数:
排序作为最基础、最常用的计算范式之一,广泛应用于人工智能、搜索引擎、路径规划、数据库等众多关键任务中。由于排序本质上的高度非线性,传统硬件通常依赖复杂的比较器网络和频繁的主存访问,在大数据时代愈发受限于带宽、能效、面积瓶颈。近年来,存算一体技术被寄予厚望,尤其是基于忆阻器的存算一体架构,因其高密度、多电导态和高能效等突出优势,已成为突破传统“存算分离”架构瓶颈最具潜力的方向之一。然而,排序等非线性计算因其高度依赖复杂比较器网络,一直被视为存算一体领域最难攻克的挑战之一。

图1:忆阻器存算一体排序系统整体示意图
在这一背景下,91直播 /广东省存算一体芯片重点实验室杨玉超教授团队在国际上首次实现了面向高复杂度排序任务的存算一体化硬件系统,提出了一个全新的、无需比较器的排序硬件架构,成功打破了存算一体技术难以处理排序等非线性计算的限制,标志着该领域实现从线性矩阵计算向非线性复杂任务的重大突破。相关研究成果以题为《A fast and reconfigurable sort-in-memory system based on memristors》的论文,近日发表在国际顶级期刊《自然∙电子》(Nature Electronics)上。
在这项工作中,研究团队首次构建了一个基于1T1R忆阻器阵列、无需比较器的存算一体排序软硬件一体系统。该工作创新的提出了忆阻器阵列位读取(Digit Read)机制,通过并行读取从高位至低位逐步定位当前最小或最大值,配合存算一体电路,彻底颠覆了传统基于比较-选择的排序架构与流程。在此基础上,研究团队进一步提出了树节点跳跃(Tree Node Skipping, TNS)排序算法及其硬件架构,利用遍历路径与信息复用,显著减少了冗余操作,大幅提升了存算一体化排序效率。为应对更加复杂的实际排序应用场景,该工作还设计了三种跨阵列的扩展策略(Cross-array TNS, CA-TNS),分别面向不同并行维度:多阵列(Multi-Bank)策略支持大量数据按数分阵列进行并行处理,位分区(Bit-Slice)策略将位宽拆分到多个阵列实现数字流水并行,多电导(Multi-Level)策略则利用忆阻器的多电导态特性提升单元内并行度,三种创新策略可根据具体排序应用需求灵活配置、组合使用,形成了一套针对可变数据位宽的完整存算一体排序硬件加速方案。
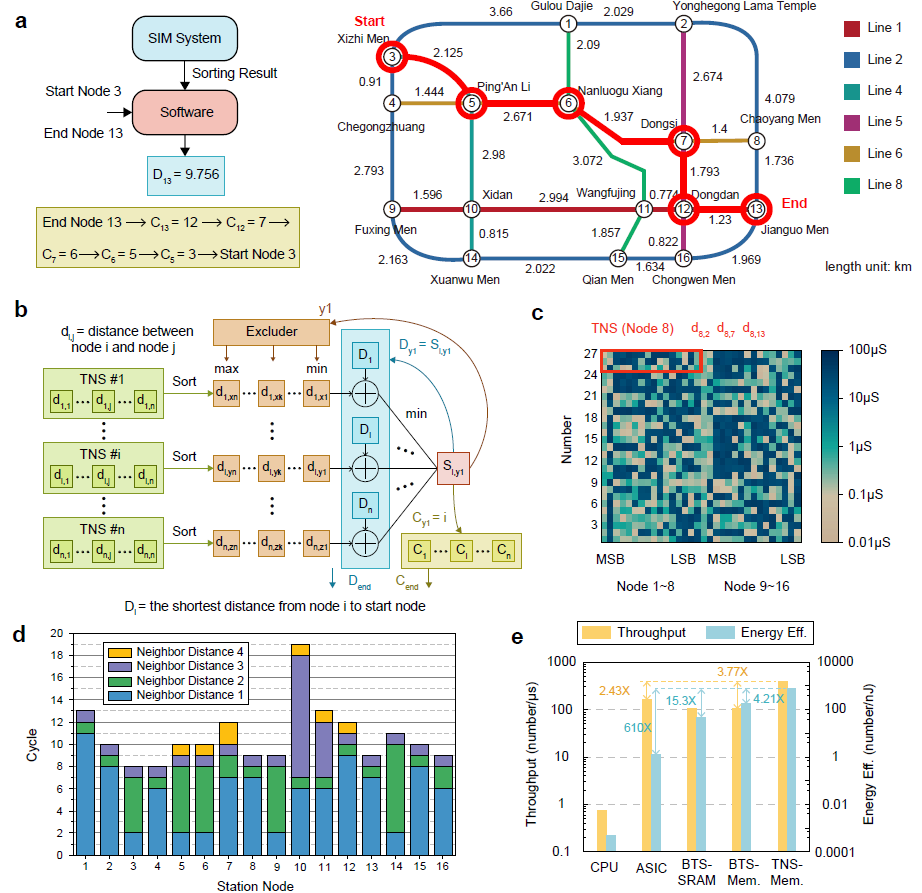
图2:存算一体排序系统实现高效路径规划
该系统基于实际流片的忆阻器芯片,结合PCB与FPGA搭建了端到端的板卡级应用演示系统,全面验证了其在多种典型排序任务中的优越性能。实验结果显示,相较于当前主流ASIC排序系统,该系统在5类代表性数据集上实现了高达7.70倍的速度提升、160.4倍的能效提升和32.46倍的面积效率提升,充分展现出存算一体架构在大数据排序场景中的巨大潜力。研究团队进一步还将该系统应用于两个实际任务中验证了系统的实用性与通用性:在Dijkstra路径规划应用中,基于TNS排序系统成功实现了北京地铁16个站点之间的最短路径求解,不仅保持运算准确性,还大幅降低延迟和功耗;在神经网络推理中,团队将TNS与忆阻器矩阵向量乘法计算融合,在PointNet++网络上实现了实时原位稀疏(run-time tunable sparsity),可根据推理精度需求灵活控制稀疏度,提升系统效率并同时降低计算开销。相较于传统ASIC排序系统,可以提升15倍的速度和67.1倍的能效。
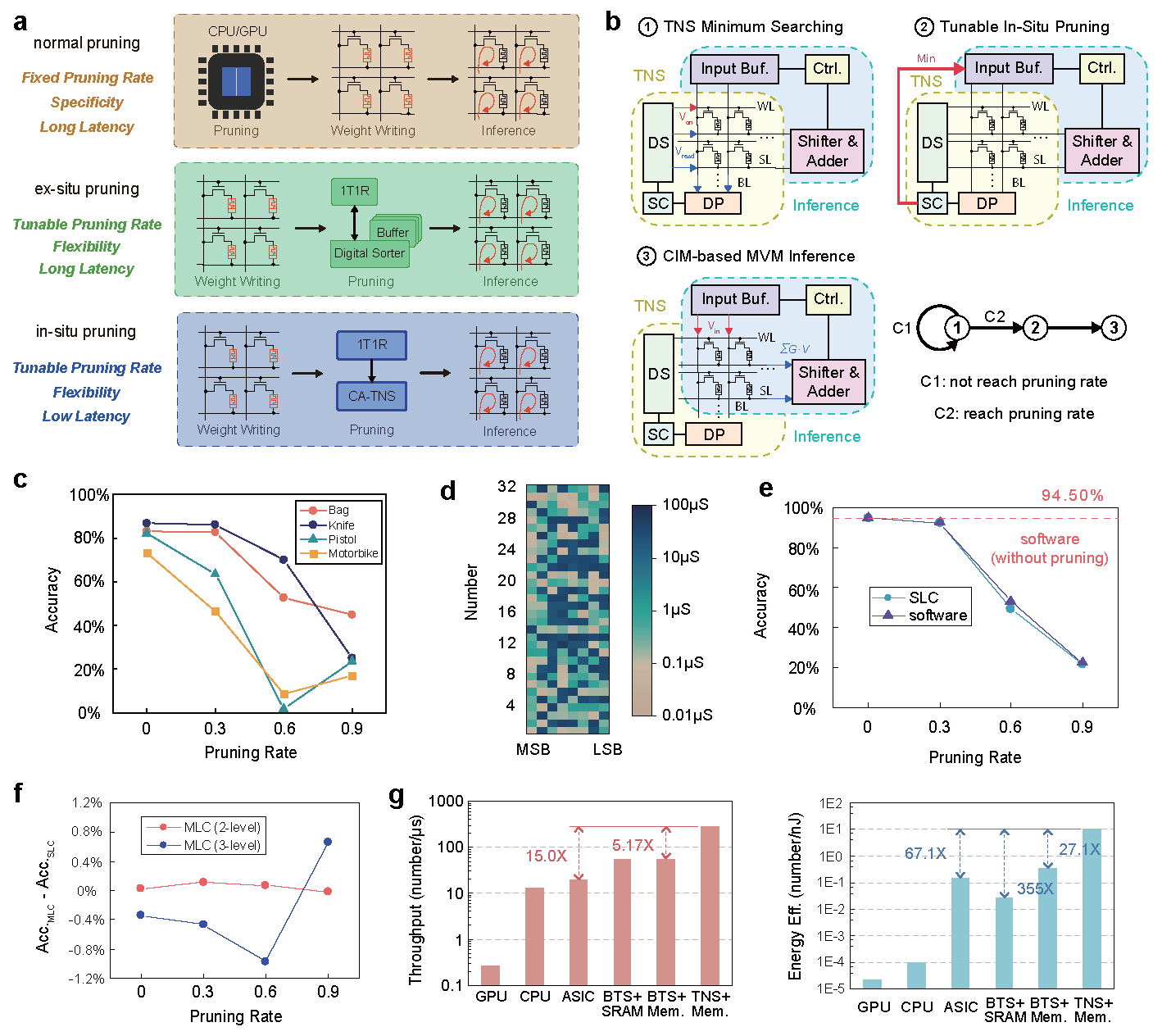
图3:存算一体排序与现有矩阵存算一体计算兼容,实现实时可变稀疏AI计算
相关成果以“A fast and reconfigurable sort-in-memory system based on memristors”为题,发表于国际顶尖期刊《自然∙电子》(Nature Electronics)。91直播 博士生余连风为第一作者,91直播 /广东省存算一体芯片重点实验室杨玉超教授与陶耀宇研究员为通讯作者。相关工作得到了国家重点研发计划、国家自然科学基金、广东省存算一体芯片重点实验室、北京市自然科学基金等项目的资助。
文章doi链接:
//doi.org/10.1038/s41928-025-01405-2